In response to a wave of high-profile software supply chain attacks, organizations are under growing pressure to harden their build and release processes. Three recently released frameworks—Google’s SLSA, Microsoft’s SCIM, and the CNCF’s Software Supply Chain Best Practices—offer structured guidance for improving software integrity and end-to-end supply chain security.
This article provides an executive overview of these frameworks, highlights their common high-assurance requirements, and explains how enterprises can practically implement them in real-world environments.
Overview of Emerging Supply Chain Security Frameworks
Microsoft Supply Chain Integrity Model (SCIM)
Microsoft’s Supply Chain Integrity Model, or SCIM for short, specifies an end-to-end system for validating arbitrary artifacts (software and hardware) in terms of supply chains whose integrity has been proven.
Rather than prescribing specific implementations, SCIM focuses on:
-
Minimum standards for preparing, storing, distributing, consuming, validating, and evaluating evidence about artifacts
-
A common language and structure for conveying that evidence across tools and organizations
In short, SCIM defines how to think about and communicate supply chain integrity, but leaves it to other frameworks and implementations to define what specific evidence must be produced.
CNCF Software Supply Chain Best Practices & Google SLSA
On the other hand, both the CNCF’s Software Supply Chain Best Practices and Google’s Supply-chain Levels for Software Artifacts follow an assurance-level approach for ensuring software integrity.
-
CNCF defines three assurance levels: low, medium, and high
-
SLSA defines four assurance levels: SLSA 1 through SLSA 4
Both frameworks emphasize securing:
-
Source code
-
Third-party dependencies
-
Build systems and pipelines
-
Build artifacts
-
Deployment pipelines and environments
They rely heavily on automation, cryptographic attestations, and strong provenance to protect these assets and prove that the software delivered to end users is trustworthy.
Vulnerabilities & Risks in the Software Supply Chain
At a high level, a typical software delivery lifecycle looks like this:
-
A developer submits code changes to a source control repository
-
A build service retrieves the source code and compiles it
-
The resulting binaries are signed and packaged
-
The package is distributed to end users or downstream projects
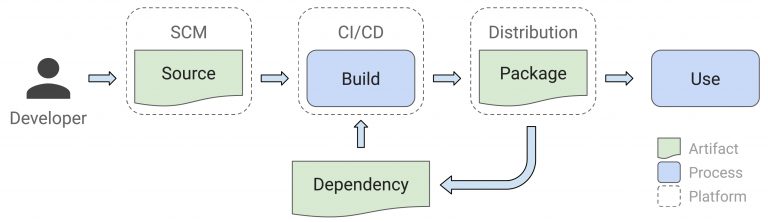
Across this lifecycle, there are numerous points where attackers can attempt to inject malicious code or tamper with artifacts. The SLSA framework documents eight primary attack vectors—covering everything from compromised build environments to tampered dependencies and malicious releases.
Real-world incidents have demonstrated that each of these vectors is exploitable. When the requirements of SLSA Level 4 and CNCF’s high-assurance level are met, these attacks are either prevented outright or detected very early in the process.
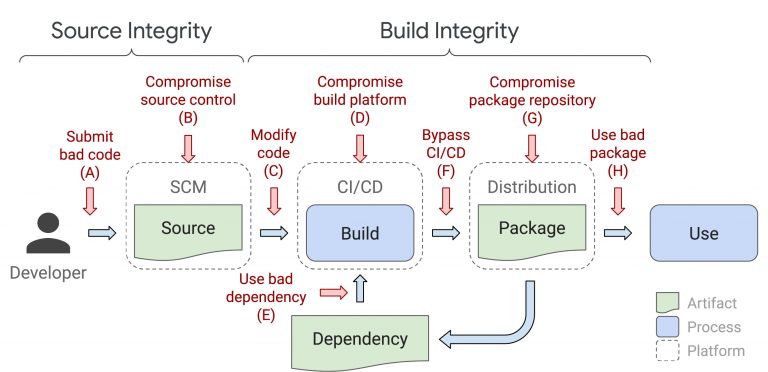
Each of these 8 attack vectors have been exploited on real businesses, as documented by both the SLSA framework and the CNCF. When all of the SLSA 4 and the CNCF high-level requirements are satisfied, each of these attacks would have been prevented or detected very early on.
Meeting High-Assurance Supply Chain Requirements
Below is a summary of the key high-assurance requirements that emerge across SLSA, SCIM-aligned practices, and CNCF guidance
1. Version Control With Verified History
Every change to the codebase must be:
-
Attributable to a specific, authorized developer
-
Authenticated using strong, preferably multi-factor authentication
-
Timestamped to record when the change occurred
In addition, all changes must be tracked in a version control system that:
-
Maintains a complete, immutable history
-
Allows any build to be traced back to a specific version and commit
In Git, for example, this means that a build can be uniquely identified by:
-
Repository URL
-
Branch/tag/ref
-
Commit ID
Both commits and historical versions of the codebase must be immutable to preserve trust in the build history.
2. Two-Person Secure Code Reviews
To prevent unauthorized or risky changes from being promoted into release:
-
Every commit destined for a final release must be reviewed by at least one qualified, independent reviewer
-
Reviews should validate:
-
Functional correctness
-
Security implications
-
Necessity and scope
-
Code quality and maintainability
-
This “two-person rule” reduces the likelihood that malicious or accidental vulnerabilities are merged into production code.
3. Automated Builds in a Secure CI/CD Environment
Manual builds on local workstations are fundamentally at odds with supply chain security. Instead, builds should be:
-
Fully automated and reproducible
-
Executed in a controlled CI/CD environment that is:
-
Isolated – Each build is unaffected by past or concurrent builds
-
Hermetic – All external dependencies are declared and resolved via immutable, verifiable references
-
Parameterless – The build output should depend only on the source code (and declared configuration), not ad-hoc parameters
-
Ephemeral – Each build runs in a fresh container or VM created solely for that build and destroyed when it completes
-
This model dramatically reduces the attack surface of the build environment and makes malicious interference easier to detect.
4. Verified Reproducible Builds
In addition to the qualities described above, the build process should be verified reproducible. For a build to be reproducible, according to the reproducible builds website.
A reproducible build is one where:
The same source code always produces the exact same binary, bit-for-bit.
Per the reproducible builds community, this requires a fully deterministic build pipeline.
A verified reproducible build goes further. SLSA describes this as:
Using two or more independent build systems to corroborate the provenance of a build.
Practically, this means:
-
The build process is deterministic
-
Two independent build servers each build the same source code
-
The resulting binaries are compared and must match exactly
If they do not match, this is a strong signal that the build pipeline or environment may have been tampered with.
Downstream Verification: Proving Integrity to End Users
Even if a software supplier implements all the controls above, end users still need a way to independently verify the integrity of what they install.
Simple checksum verification only confirms that:
-
The downloaded artifact matches what the supplier intended to provide
It does not verify that:
-
The artifact was built from the correct source code
-
The build followed a secure, compliant pipeline
In theory, an end user could:
-
Obtain the source code and build instructions
-
Reproduce the build locally
-
Compare the resulting binaries
But in practice, this is operationally infeasible—and often impossible when source code is not publicly available.
Attestations: Scalable, Automated Verification
A more scalable approach is to use cryptographic attestations that devices can verify automatically at install or runtime. Attestations can encode:
-
What was built
-
How it was built
-
Which controls (e.g., SLSA level) were satisfied
A natural design is to maintain a central attestation repository that clients can query. However, this approach has several challenges:
-
All consuming devices and tools must be updated to:
-
Query the repository
-
Parse and interpret responses
-
Enforce policy based on the results
-
-
Some devices may lack reliable network connectivity
-
Repository downtime could:
-
Block installs or updates
-
Disrupt running applications
-
-
Devices must know which repository URL to query and how to validate it.
Embedding Attestations: Tradeoffs
An alternative is to ship attestations alongside the binaries:
-
Baked into the binaries:
-
May break backward compatibility with existing tools
-
Requires updates across the ecosystem to understand new formats
-
-
Packaged together (e.g., binaries + attestations in a single archive):
-
Tools must be updated to recognize and process the new package layout
-
Both approaches introduce friction and compatibility concerns.
A Pragmatic Alternative: Stronger Semantics for Code Signing
A more practical option is to build on an existing, widely deployed mechanism: code signing.
Today, code signing is generally interpreted to mean:
-
The signed binaries were produced (or at least released) by the holder of the code signing key associated with the certificate.
We do not want to change that meaning for standard use. However, many ecosystems already support different assurance levels for signatures:
-
Standard vs EV (Extended Validation) code signing certificates
-
In the PGP world (e.g., RPM, Debian), public keys can be signed by auditors or other trusted entities to elevate their trust level (web of trust)
Using these existing patterns, higher-assurance signatures can be defined to mean:
The signer has been audited and verified to follow a process compliant with SLSA Level 4 (or an equivalent framework/level).
This model yields several benefits:
-
Downstream tools rarely need to change—signature verification is already implemented
-
Validation can be fully automated using existing trust chains
-
Certificate Authorities (CAs) can extend their issuance process to:
-
Audit software vendors’ supply chain practices
-
Issue specialized certificates only after compliance is proven
-
For organizations that want deeper insight, additional metadata can be layered in:
-
An X.509v3 certificate extension can point to an attestation repository URL
-
In PGP, the same URL can be added to the key’s comment field
This allows advanced tooling to fetch build-specific attestation artifacts without disrupting existing verification flows.
Build Systems & Cryptographic Services
If a trusted signature on the binaries is meant to signal compliance with a high-assurance framework the code signing process
itself must:
-
Validate that each build complies with the required controls
-
Enforce these checks before generating any signature
In a manual release process, this could theoretically be handled with checklists and human approval—but that approach does not scale to modern DevOps or CI/CD environments.
If the signing keys are compromised, there is no trust in the system, which means that the first priority is to properly protect the keys. Once protected, infrastructure is needed to securely and efficiently use the private keys for signing. We have written about this at great length and we encourage readers to read our previous posts on these topics. The summary is that a secure signing service that supports hash-signing, keys protected by a hardware security module (or key management system), and strong authentication/authorization is the optimum solution.
With the keys properly protected, the next challenge is satisfying the verified reproducible build requirement. To achieve this, the signing system can make use of one or more separate verification servers to independently verify the hash to sign as part of the code signing system. We have written about this in detail before, but the basic idea is shown below.
Verified Reproducible Builds via Independent Verifiers
To satisfy verified reproducible build requirements:
-
The signing service can integrate with one or more independent verification servers
-
These verifier servers:
-
Rebuild the source code
-
Confirm that the resulting hash matches the hash presented for signing
-
Only when the independent verifier(s) attest that the build is valid does the signing service issue a compliant signature.
This pattern allows enterprises to centralize:
-
Key protection
-
Policy enforcement
-
Verification of build integrity
…without tightly coupling these responsibilities to a single build system.
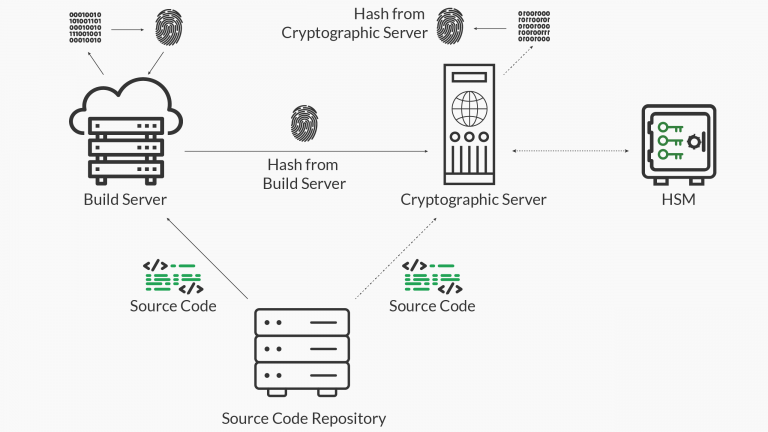
The video below shows what this process looks like in action.
Enhancing Performance Without Sacrificing Security
A common concern is that verified, high-assurance build processes will slow down CI/CD pipelines. With careful architecture, the opposite can be true.
One effective pattern is:
-
Generate the code signing signature immediately after the main build completes
-
Run the verified reproducible build in parallel on a separate verifier server
-
If verification later fails, treat it as a critical incident:
-
Investigate the cause
-
Revoke or replace compromised artifacts if necessary
-
This approach allows:
-
The primary CI/CD pipeline to progress without waiting on the full verification cycle
-
Additional tasks—such as advanced security scans and compliance checks—to be offloaded to the verifier infrastructure
Compared to a single linear pipeline, a parallelized architecture can actually reduce overall build completion time while increasing security.
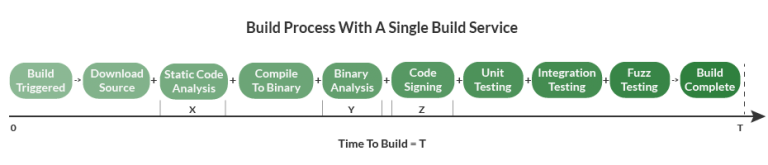
Here’s what the build process looks like when it is completed in parallel on two servers:
With tests and scans offloaded to the cryptographic service, the build completes faster than it would with just one server performing every task, one at a time.
The video below shows what this looks like in action.
Protecting the Source Code
With the features above implemented, software suppliers have strong assurances that only code originating from the source code repository will get signed. The next step is to ensure that the code in the repository is “good”. This translates to ensuring that only valid users are making changes to the repository and that the changes that are being made are valid.
We have written about this in detail before but ultimately this boils down to using strong authentication and authorization (e.g., multi-factor authentication, device authentication, commit signing, etc. combined with the principle of least privilege), having every commit reviewed by a qualified reviewer, and scanning the code and resulting binaries with automated tools (e.g., SAST, DAST, fuzzing, etc.). If a source code repository doesn’t support advanced authentication techniques, they can be transparently enforced by using key-based authentication with proxied keys.
Putting This Into Practice
While this may sound like a lot to accomplish, it is easy to do with GaraTrust and deployments can be done with minimal intrusion to your existing environment.
Get in touch with the Garantir team to learn more about deploying a secure software supply chain process for your enterprise.